这是我给公司同事做的内部培训ppt的讲义,给大家分享一下。这是培训大纲,ppt在找地方上传,等找到了会把链接发在这里 。
暂时放在csdn上,赚点下载积分:https://download.csdn.net/download/kingstarer/10655069
截几个ppt页面大家可以先预览一下





大家好,欢迎大家来参加今天的技术交流,而今天打算跟大家分享的是oracle数据库应用优化相关的一些经验。这是大纲。
我们今天要讲的内容分五部分。其中1到3是我们今天重点交流的内容,然后四和五的话就可能,稍微快一点就带过。
我先给大家简单介绍一下每个部分的内容。
首先第一部分会给大家介绍一下oracle数据库的架构及一些内部实现细节。这是为了给后面介绍数据库优化知识做一些铺垫。
接着,我想给大家介绍一些编写高性能sql的经验。
然后在第三部分,我们会分享一下数据库的执行计划相关知识。我们平时发现sql跑得比较慢时,就可以查看执行计划,找出里面不合理的环节进行优化。
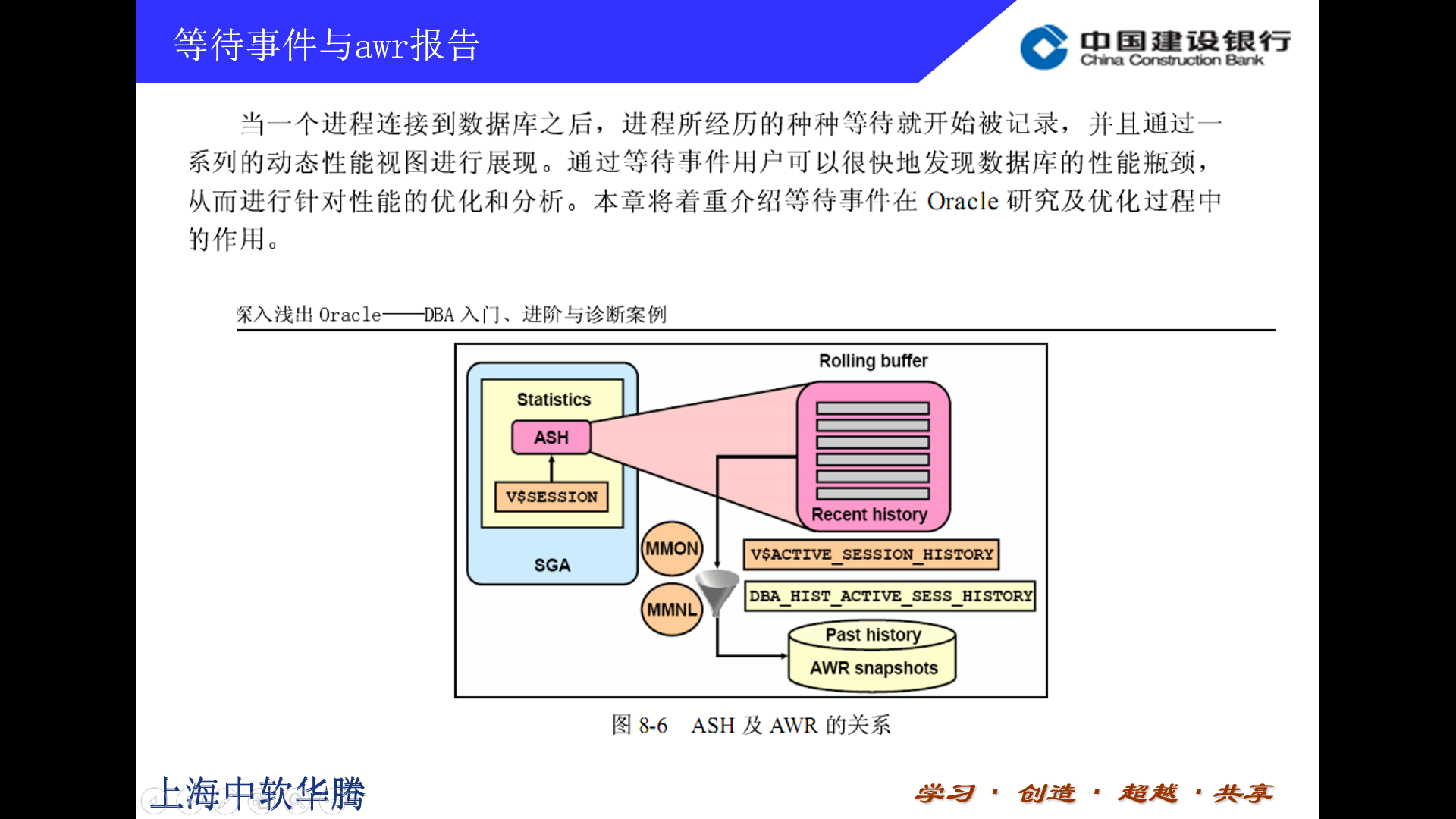
第四部分内容是关于数据库等待事件及awr报告的一些优化的内介绍。awr报告相当于数据库的体检报告,等待事件就是一些体检指标。我们做整个数据库应用优化经常用到它。
第五部分的话是一些学习资料推荐。
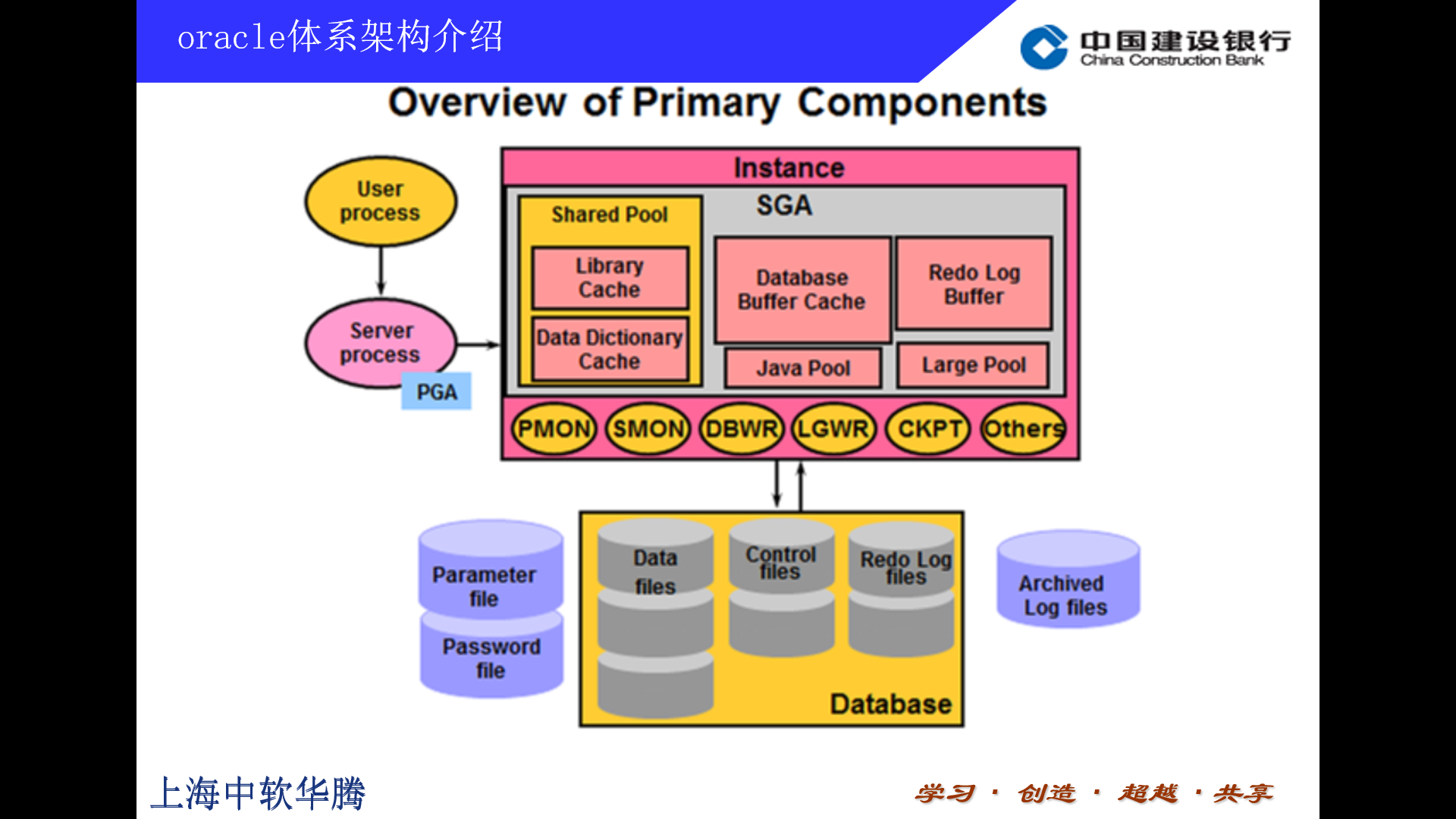
下面我们开始进入第一部分内容的介绍。这是,一个oracle数据库的架构图。
这里user process是客户端进程的意思,也就是我们平时自己写的程序,或者sqlplus sqldevelor这些工具。
我们平时说的数据库是一个比较模糊的概念,其实它是包含两部分组成。一部分是数据库文件,包括数据文件,日志文件等。也就是这一部分,这个才是专业术语的数据库database。 另一部分是数据库实例,一套围绕真数据库运行的进程集合。
这里要说明一下的是,不是比较旧的,我从网上抄下来的11g架构图。现在数据库都已经出到18c了,可能会有一些变化。另外,这图里面有一些不是太重要的数据库进程,这里是没有发出来的。嗯,我们还是看这张图吧,这图估计是oracle8i时出的图,虽然比刚才的图缺少了一些内容,但我觉得画的更好一些,所以后面会围绕这张图来介绍。
从这图可以看出来,oracle数据库主要分两部分,一部分是数据库实例,由数据库后台进程和相关的共享内存组成。另一部分,就是DataBase这一块,主要是数据库文件。我们常说的数据库是对这两块内容的统称。
这图还是挺重要的,大家多看几眼。接下来我们会对这图里面出现的名词做一些详细介绍。
接下来,我们对数据库的一些重要组件,逐个介绍吧。
首先要介绍的是数据库实例这块。这一块由两大部分组成,一个是这个,巨大的共享内存块,我们称之为SGA。另一块是oracle后台进程。
SGA是非常重要的概念。它主要是做为oracle库表数据和重做日志的缓存和缓冲。下一页我们会详细讲里面具体细节。
这一页我们重点要介绍的是oracle数据库后台进程。这些后台进程主要负责数据库监控,数据与日志读写,故障恢复等功能。
这里我们列出几个比较常见的进程介绍。 Pmon和smon,这两个进程分别用与用户进程故障和系统故障恢复的。我们开发一般不需要关心它的工作原理,dba才需要关注。
DBWN这个进程负责把SGA里面的数据写回磁盘。我们刚才说过SGA缓存了oracle数据库表数据。里面有部分数据是用户用sql修改过的,需要写回磁盘。因为数据库写磁盘比较耗时,所以数据修改总是先在SGA中修改,达到一定量或者数据库空闲时才由DBWN统一写回磁盘。
LGWR也是一个比较重要的进程。它负责把Redo日志从内存中写到磁盘,用于数据库恢复。一个事务只有将Redo日志写到磁盘才能算完成。LGWR主要工作时间点是用户发起commit命令时,或者日志缓冲区超过1M时工作。
Redo日志大小有限制,写满后会通过归档日志进程转移到归档日志里面。
CHKP是协调LGWR和DBWN的进程。详细协调原理大家有兴趣可以上网找找,我这里主要想介绍它们之间协调需要用到的一个概念,叫系统变更号,也就是这个SCN。这个系统变更号我们可以简单理解为是oracle事务的编号,它是随着事务提交与时间变化而增长的。Oracle每个数据块都会记录修改该数据块的系统变更号。数据库做查询时,可以根据这个系统变更号判断记录是否已经最近被修改过。
下面详细介绍一下SGA的组成。
数据库块缓冲缓存区,这个主要是缓存数据库的数据的。包括读写数据,都会先放到这个缓冲区,有空再写回磁盘。一般交易系统这个缓冲区的命中率是很高的,超过90%。
Library Cache是一个缓存,但它缓存的不是数据,而是sql以及执行计划。Oracle数据库在执行sql前,先要生成sql的执行计划,也就是sql的详细执行步骤。这个步骤生成是相对比较消耗数据库资源的。所以oracle会把生成的执行计划暂存起来,后面如果碰上一模一样的sql,就直接用现成的执行计划,不用再重新生成。所以我们平时写sql经常说要用绑定变量,一个主要原因就是减少数据库执行计划生成的时间。
重做日志刚才有稍微提到,它是数据库变更的记录。例如我们发出一个update语句,把一个字段从0变成1,redo日志就会记录这个字段变成1之后的数据。数据库修改一条记录后不会立即写回磁盘的,而是先写到缓存同时登记重做日志。在事务提交时,只要把重做日志输出到磁盘,这条记录就不会因为断电丢失。因为一般来说,写数据时随机IO,写日志是顺序IO,顺序IO速度比随机IO快很多。
与Redo日志对应的是Undo数据。它是存放个Undo表空间。Undo就是撤销,与重做是相反的过程。所以我们把字段从0变成1时,这里会记录的是字段在改变前,仍然是0的数据。
注意Undo表空间的数据是存放在数据库文件的,所以数据库在操作回滚段时也会在Database Buffer Cache进行缓存。
Undo数据有一个非常有用的作用,就是一致性读。Oracle执行select语句时一般是不锁表的,但是它还是会保证返回的数据肯定是查询开始时间点的数据,即使查询过程中,数据被修改过。这功能实现就是需要通过查询回滚数据,获得数据在修改前的状态。
这是检查点的原理,检查点是用于数据库断电恢复的。大家有兴趣自己细看。
数据库实例介绍完,下面我们开始介绍Database这块。Database是数据库文件集合的统称,一个Database可以对应多个数据库实例。我们常说的rac就是这样,多个数据库服务器,操作同一个数据库文件。
数据库里面最重要的文件就是数据文件和联机日志文件。刚才我们有介绍过Redo日志缓存,它在用户提交事务时就会写到磁盘,就是这个联机日志。
这一页介绍的是oracle数据库服务进程的知识。也就是处理我们平时写的客户端程发出的sql请求的进程。
一个数据库会有很多个服务进程,这些进程共同享一个SGA。但每个进程都有自己的一块私有内存空间,我们称之为PGA。PGA默认是比较小的,如果我们需要进行大表连接,可能会嫌内存不够用,这时我们可以申请把PGA加大。做批量任务的同学可以注意一下。
但是有两部分SB哎,就是这一块的内存,然后呢?他还有另外一部分就是这个这些相关的一些后台进程是比较重要的,这是一块巨大的共享内存,然后呢?它主要的功能的话就是做一个化充实这样这些数据快让我们愉快这些都会在里面存,然后这个数据是这些后台进程,后来进程,包括上面这几个,这个是每一个进程具体布置的东西监控的这个不是太重要,然后这个这个屁吗?这个是用户进程监控这个主要用于挂了的话就没有正常断开的情况下,他会帮你把这些原来重要,然后这个这个事,let这个这个这个作用的话是吧,就我们曾说过,里面有几块就是把数据库缓存的一些数据写回,然后呢。这个night。我只要。驶入池塘。日志写入进程就是跟我们数据库在定期。写到日志文件。这个是匡威。归档归档进程,这个呢是这个适用于这里面其实比较重要的话,就是需要关心的是这两个进程,不要进程的相关知识。这里。这里是oracle数据库的一些原理。这是系统改编号,就这个事,日志进程他。他有时候。接下来我们介绍这一块数据库相关的知识。
下面让我们通过一个update语句的执行过程介绍来串讲刚才介绍过的知识吧。首先,客户端会发起sql执行请求,数据库会到缓冲池里面查找该sql执行计划是否存在。如果存在则使用现成的执行计划,这个过程称为软解析。如果执行计划不存在则需要重新生成,这个过程叫硬解析。接着数据库会分析sql需要访问的数据,看是否在数据块缓存里面。如果是则直接使用缓存数据,如果不是则需要从数据库文件读出来放到内存。
接着数据库会在内存中修改数据块,并且同时登记redo日志到日志缓冲区。
等到数据库提交时,redo日志的内容就会被刷进磁盘。数据缓冲区的内容则过一段时间由dbwn写进磁盘。
关于数据库的主要架构介绍到这里。 这几页是数据库块的细节知识介绍,由于时间关系就不讲了。大家主要需要知道,oracle一次硬盘操作都是以数据库块为单位的,而不是以一行记录或者一个字段为单位的。一个数据库块会有n行记录。
下面进入重点交流的内容,关于数据库应用优化的知识。
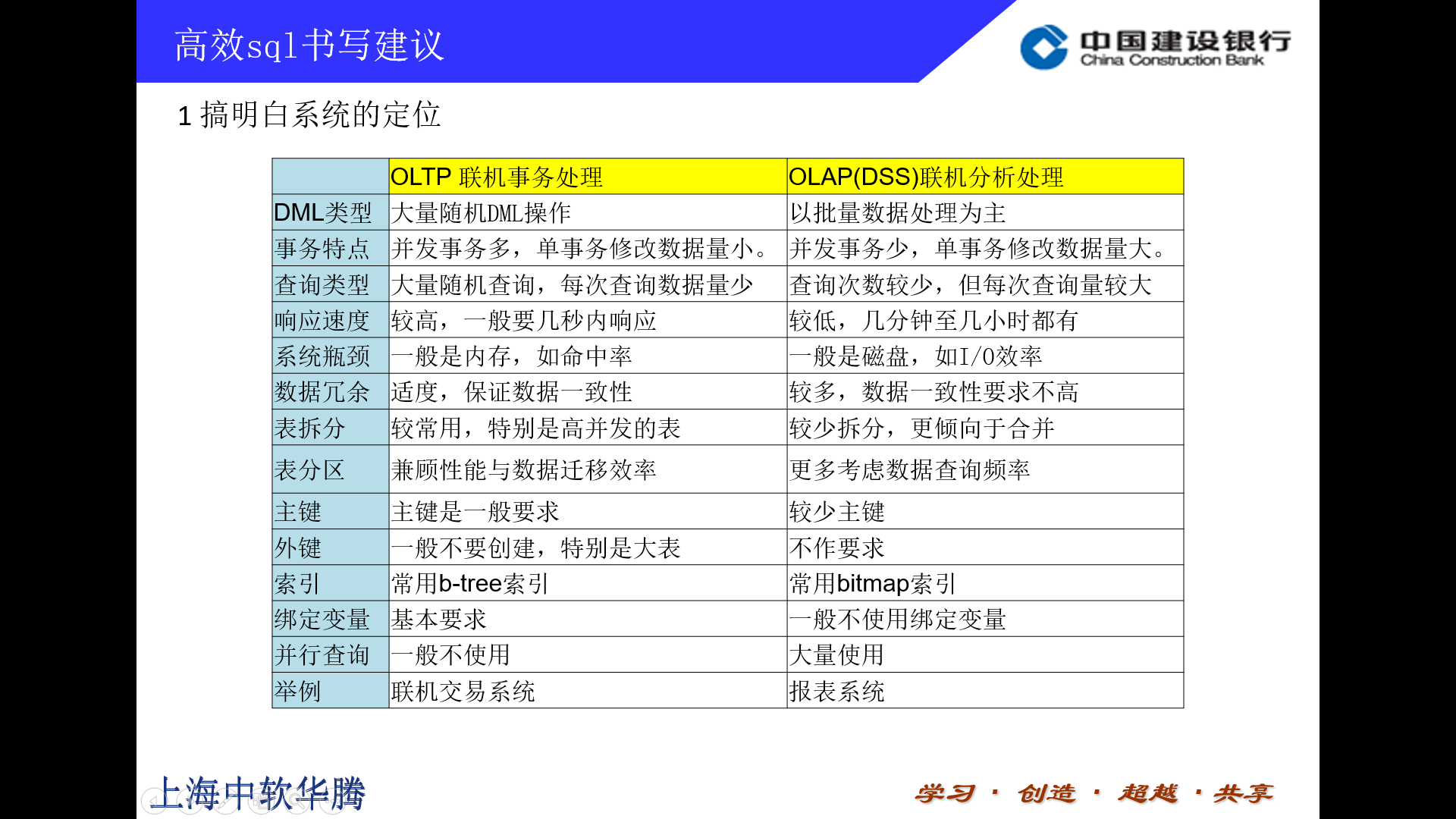
首先,我们在数据库优化时要注意系统的类型,不同系统的优化目标是不一样的。一般来说,我们把系统分为两大类:OLTP和OLAP,也称DSS。
OLTP全称是在线交易系统,像我们的收单联机系统就属这类。这类系统的特点是:交易非常频繁,但每次交易涉及的数据量很少。对数据库响应时间要求比较高,一般要求几秒甚至几毫秒内返回。
OLAP全称是联机分析系统,我们平时做的批量系统就属这类。这类系统特点时:交易比较少,但每次交易涉及数据量比较多。数据库访问时间要求相对宽松点。
Oltp系统常见资源瓶颈是在cpu和内存上,而oltp系统常见问题是出在io上面。
这个表格介绍了两类系统开发的一些经验。
OLTP由于sql运行频次较高,一般要求使用绑定变量,减少数据库生成执行计划的消耗。另外,OLTP一般要尽量减少访问数据库磁盘的次数,尽量提高内存命中率。
在线分析系统一般是读写比比较大的系统,为了数据访问方便会做很多冗余。并且,为了数据库能得出最优的执行计划,使用绑定变量会少一些。
这是一般两类系统在装数据库时的参数配置差异,也是遵循系统业务特点而配置的。
前面一节介绍了系统优化的总体原则,这里会介绍一些优化细则。
首先是关于索引的。
索引告诉数据库有什么,而不是没有什么。所以我们平时用的不等于查询条件是用不上索引的。
另外,索引列的数据类型我们也要注意。像这种情况tel电话号码列用的是字符串类型,但查询时却是用tel=数字这样的。会导致数据库索引无效。还有,像这种,我们看起来是数学等价的操作,但却会因为索引的问题导致效率相差很多。
还有这个也是常见误区。不是使用索引不一定比不使用索引快。按我们平时经验,数据库里面少于100条记录,或者索引列选择比不高,例如性别字段只有男或者女,使用索引反而慢一些。因为数据库使用索引查询时需要先在索引里面做几次磁盘操作,然后找到记录位置后还要再回表数据访问记录内容。
这条经验也比较重要,如果我们数据库里面有使用外键保证数据一致性,那要注意在建了外键的列上建索引。因为oracle修改父表记录时需要到子表检查修改后记录是否会违反外键约束,不建索引会很耗时。
这一页想介绍的是oracle一些特性,这是oracle独有功能。用好这些特性可以在某些特定场景大大优化我们程序。
这一条,讲的是oracle的rownum和rowid用法。我们平时写脚本经常会出现这样的场景:如果库表有记录,则执行a操作,否则执行b操作。有些同学会很自然地用select count(*)来判断库表是否有记录。其实我们可以在后面加上where rownum < 2这样的限制,这样做是告诉数据库只要找到符合条件的记录就可以结束查询,不需要统计完所有数据。
Rowid概念前面的ppt页有,使用rowid访问记录是oracle访问数据最快的方法,因为rowid明确表达了数据在磁盘哪个文件,哪个数据块,哪行记录。比索引访问要快,用索引访问时需要先查出rowid再根据rowid查对应的数据。
还有这个技巧,相信做批量的同学也经常用到。就是使用一些特殊方法让数据库不要记录redo日志。前面我们介绍过,对数据库操作都需要记录redo日志用于数据库出现异常时恢复数据,但如果我们确定数据不是太重要,数据库异常挂掉后不需要恢复,则可以使用这些小技巧减少redo日志以加快速度。
还有一些其它不成体系的技巧,这里也介绍一下。
这个是大家比较熟知的,使用绑定变量,可以复用sql执行计划,减少数据库cpu消耗。
这个技巧大家应该也知道,就是删除整个表数据时,尽量考虑使用truncate。因为truncate是直接修改数据库字典,把库表占用数据空间状态改为未使用。这样操作是很快的。不过要注意的是truncate不像delete,误删后可以回滚。Truncate一执行后就会自动提交事务,并且无法闪回查询。
接下来这一大章想要给大家交流的是关于数据库执行计划的一些知识。前面一章介绍的一些优化经验,这一章说的是一个优化的通用方法:通过调整执行计划改善sql运行效率。
首先介绍一下执行计划的定义。执行计划就是数据库执行sql语句的步骤计划,oracle在执行sql之前会先将复杂sql拆解成一些简单步骤并依次执行。
同一个sql可以有很多个不同的执行计划,这些执行计划效率差别可能很大。
我们怎么看sql的执行计划呢,这里介绍几个方法:
一个方法是在sqlplus里面执行set autotrace on,然后再执行sql,执行完毕后sqlplus就会打印sql执行计划及一些统计信息。
还有一种,不需要执行sql,只需要执行explain命令,接着就能用sql语句查出它的执行计划。
还有一种,我比较常用的方法。在plsql develor的执行计划窗口中运行sql,也可以显示执行计划。就像这边这个图片一样。
知道怎么看执行计划后,我们还要懂得怎么分析。
我们看这个简单的sql的执行计划,可以看出来,执行计划是树型结构,有很多个步骤组成,每个步骤都可能有子结点或者兄弟结点。
我们看执行计划时需要从上往下看,碰到有子结点先后子结点,如果没有子结点,则同一层级的兄弟结点中比较靠上的一个,看完再看另一个。
或者我们可以借助工具来帮我们确定执行计划执行顺序。这个就是plsql里面看执行计划的窗口,这里有一组箭头,点击它会依照执行顺序选中执行步骤。
我们拿一个具体案例做一下讲解:
这个sql作用是从雇员表里面找出工号小于103的数据,关联职位表取出职位信息,关联部门表取出部门信息。
它对应的执行计划是这样的
我们从上往下看,0 1 2都有子结点,所以先看它们的子结点。一直看到3,3没有子结点,所以先执行3。从雇员表里面取出数据。
3执行完后需要执行它的兄弟结点4,4有子结点,所以先执行它的子结点5,用job_id到索引job_id_pk里面找数据的rowid。5执行完后会根据找到的数据rowid回到职位表里面找出职位信息,也就是4这个子节点的操作。
3和4执行完后就要回到2,把数据连接到一起。然后再执行6和7,从部门表里面取出数据,接着执行1再把部门数据跟前面的雇员与职位表连接结果再合并,最后回到0,返回客户端。
所以这个执行计划的执行顺序就是3 5 4 2 7 6 1 0
像这个是比较复杂一点的执行计划,大家有兴趣可以自己回去看它的执行顺序。答案在这一列。
前面我们说过,同一个sql会有很多不同执行计划。那数据库怎么确定使用哪个执行计划呢。这就涉及这章要介绍的,优化器的概念。
优化器是数据库的一个核心组件,负责将sql根据各种判断标准转换成最优的执行计划。
现在我们用的优化器都是cbo,基于成本计算的优化器。它会计算每个sql执行步骤的成本,挑选总成本最低的执行计划。
前面我们说过,oltp和olap系统优化目标是不同的,一个是注重响应速度,一个是注重资源消耗。所以oracle也为cbo提供了两种工作选项,一种是first_rows,适用于oltp系统,另一种是all_rows,适用于olap系统。
两种模式下,同一个sql选择的执行计划可能相差很大,导致运行消耗的时间资源也大不相同。
为什么不同执行计划会导致差异这么大呢,主要是由于数据库表连接方式不同造成的。
这是oracle常见的四种数据库表关联方式。
我们看刚才的sql执行计划,这里的1和2都是将两个数据源进行关联。
这里关联方式都是使用嵌套关连。嵌套关联的原理是依次取出驱动表的记录到内层表寻找符合条件的连接数据。显然,这种情况下要内层表查找起来比较快,有索引或者记录数比较少。而且外层表数量越少越好,这样可以减少到内层表查数据的次数。
嵌套关联有一个好处,可以很快的返回符合条件的前几条记录。所以一般oltp系统使用嵌套关联比较多。
Oracle还有一个比较常用的连接方式,就是这个哈希连接。哈希连接原理是先将一个表在内存中做成哈希表,接着访问内层表的数据,逐个到哈希表里面查看是否有对应。
哈希连接适用于内层表没有索引,或者连接两个表记录都相对比较多的情况。Oltp系统用这种连接方式比较多。
由于连接算法不同,对系统资源消耗和响应时间也会有很大差异。
Oracle还有其它两种连接方式,但平时用得不多,这里不说了。
除了连接方式外,数据访问方式也是执行计划效率差异的主要原因。
还是举刚才的例子,这里面有好几种数据访问方式,对不同表采用了不同的方式。
有全表扫描,也有索引扫描。
全表扫描,顾名思义,就是对整个表的数据依次扫描。一般要求表的数据量比较少,或者符合查询条件的数据占全表数据比例较大的情况。
索引访问,跟全表扫描就相反了,适用于表数据量比较大,而符合条件的数据比较少的情况。
索引访问的方式有这五种,从上到下消耗的资源依次增大。
索引唯一扫描 适用于where条件直接指定主键的情况
索引范围扫描 适用于大于,小于这种where条件
索引全扫描 与全表扫描类似,它是扫描整个索引的数据。应用场景是索引字段能包含select返回字段的情况
索引快速全扫描 就是快速的索引全扫描,因为快,所以可能返回的是无序的记录。索引默认是有序的
索引跳跃扫描 适用于where条件没有指定索引前导列的情况,并且前导列选择性比较低的情况。例如建了性别和姓名的联合索引,但查询时只限制了姓名为黄词辉,没限制性别。Oracle会分别查询女性的黄词辉和男性的黄词辉,把结果合并起来
我们平时看的执行计划主要就是查数据并连接,掌握了它们的原理,我们就可以靠自己的开发经验来判断这个执行计划是否足够优化。
=============================================================
如果觉得这篇文章对你有用,扫个支付宝红包或者打赏几毛钱吧^_^,写这文章也费也不少力气。您的支持是我最大鼓励。

